
Money, Math, and Mistakes: Training Sophisticated Neural Networks for the Realities of Banking
- Jeff Hulett

- Jan 11
- 15 min read
Updated: Apr 29

Introduction: Bridging the Gap
As you begin your journey into the world of data science, it is easy to focus entirely on the "how"—the code, the math, and the algorithms. However, in the world of banking, the "why" and the "where" are just as important.
This session is intended to provide you with the professional context for how neural networks and related predictive modeling are actually deployed in a highly regulated industry. We will explore the "translation gap" between a laboratory model and a real-world lending decision, where practical constraints like law, ethics, and governance often dictate the math we are allowed to use.
Who is this for? This narrative supports a Financial Services data science experienced guest lecturer. The target audience is undergraduates in Business Analytics or Business Statistics-related programs.
The Evolution of the Credit Decision
Why do banks use models or algorithms to make credit decisions? In the "old days," loan officers manually reviewed paper applications and credit files to make individual judgments. Today, this is done by scoring models like the FICO score.
The reason for this shift is simple: scoring models are faster, lower cost, and more accurate. This transition has enabled a massive increase in the availability of credit at lower interest rates. But while you might not see as many traditional loan officers, it doesn't mean the banks fired everyone—the work has simply shifted. Credit analysis has moved from the branch office to the desks of Data Scientists and Credit Analysts. The work has become less judgmental and more analytical, requiring a deep understanding of how these mathematical "engines" actually learn.
The Foundation: Understanding the Past
A Data Scientist's journey begins with Descriptive Statistics. This is the "rear-view mirror" of banking. By calculating the mean, variance, and distribution of past loan performances, analysts build a foundational understanding of what has already happened. You cannot predict where you are going if you don’t know where you have been. Descriptive statistics provide the "History Book" grounding models in reality.
The Value: Predicting the Future
However, a bank does not make money by simply documenting the past. Business value is created at the Decision Point—the leap from descriptive "hindsight" to predictive "foresight."
The true power of a Data Scientist lies in the accuracy of their Inferential and Predictive models. Using techniques ranging from linear regressions, complex Neural Networks, and randomized control trials, they transform historical data into a "windshield" for the future. These mathematical engines aren't just academic exercises; they are the primary tools for:
Increasing Revenue: Identifying "hidden gem" borrowers who are likely to repay but might be overlooked by traditional math.
Decreasing Loss: Flagging high-risk patterns before a default occurs, protecting the bank's capital.
The work has become less judgmental and more analytical, requiring a deep understanding of how these mathematical "engines" learn. In the modern bank, the goal isn't just to do the math—it's to use that math to minimize mistakes and maximize the accuracy of the next "Yes" or "No."

Next, we will share the process for implementing neural networks or related inferential statistical approaches in the banking context.
The Setup: The "Time of Decision"
Imagine you are a bank executive deciding whether to approve a loan. At the Time of Decision, you don’t know the future, but you have a folder full of historical data—these are your Independent Variables or Features describing the borrower characteristics at the time a loan decision needs to be made. (e.g., credit utilization, payment history, credit inquiries, and income).
The outcome you want to predict (Did they default or not?) is the Dependent Variable. In our historical data, this is recorded as a 1 (Default) or 0 (Paid in full). Our goal is to tune a model that looks at those features and gets as close to that 1 or 0 as possible.
Phase 1: The Mechanics of Learning
1. The Forward Pass (The Weighting Game)
When we start training a neural network, the model begins with a "best guess." It assigns a numerical Weight to every feature. Think of a weight as the Importance Score or Sensitivity of a specific piece of data.
In the Forward Pass, the model takes a customer’s data and multiplies each feature by its assigned weight.
For example, if the model thinks "Past Delinquencies" is a huge red flag, it will assign that feature a high weight.
If it thinks "Favorite Color" is almost irrelevant, it assigns a low weight.
The model sums up all these weighted inputs to calculate a single prediction. The goal of this calculation is to see how close the current weights can get to correctly predicting the Dependent Variable (the 1 or the 0). On the first try, the weights are often random, so the model might predict a 0.50 feature weight (a coin flip) for someone who actually defaulted.
2. The Loss Function (The Scorecard)
We compare that prediction to reality. If the model predicted a 20% chance of default, but the customer actually defaulted (a 1), our model was wrong. We use a Loss Function (like Mean Squared Error or MSE) to quantify exactly how far off we were. Think of the "Loss" as the financial penalty the bank pays for being wrong.
3. Backpropagation (The Post-Mortem)
Once we know the error, we have to figure out which weights are to blame.
Backpropagation is like a bank manager conducting a post-mortem on a bad loan. We work backward from the error at the end of the process, through the layers of the network, to the beginning.
Using a calculus tool called the Chain Rule, we calculate exactly how much each weight contributed to the final error.
If the "Income" weight was too low, causing us to miss a default risk, Backpropagation calculates exactly how much to nudge that "dial" to improve the next guess.
4. Iteration (The Learning Loop)
This is an iterative process. The model performs a forward pass, measures the error, and uses backpropagation to adjust the weights. It repeats this thousands of times across your entire historical portfolio until the weights are tuned so precisely that the error can get no lower.
The Reality of Imperfect Information
How a Banker Data Scientist views the world
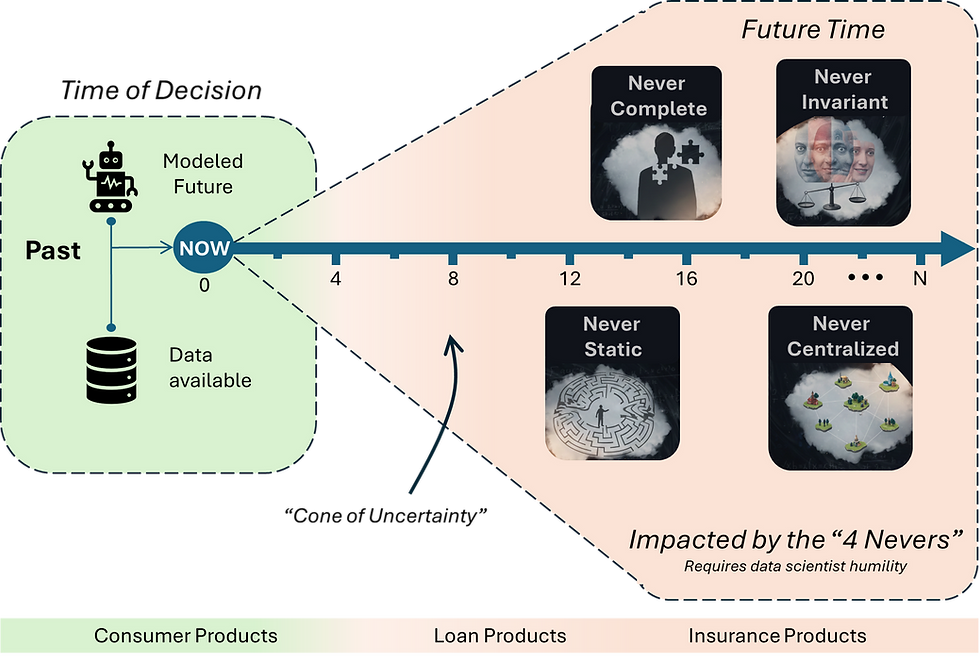
It is important to clarify: even the model with the least error is still not perfect. Default occurs years or even decades in the future, and the data we have at the Time of Decision is permanently impacted by the "Four Nevers"— data is Never Complete, Never Static, Never Centralized, and Never Invariant. These constraints mean we "never" have perfect information. The 4 Nevers combine 3 risk and uncertainty concepts called Epistemic Risk, Aleatory Risk, and Deep Uncertainty.

A neural network will only predict future probability based on imperfect information about an uncertain future. The objective is to make the model as robust as possible to inform the best credit decisions: both determining if we should make the loan and, if we do, establishing the appropriate Risk-Based Pricing. A customer with a higher predicted chance of default will pay a higher interest rate to compensate the bank for the risk taken, and vice versa.
Next, we will discuss the specific constraints the bank faces when using these models to make lending decisions in a regulated environment.
Phase 2: Practical Constraints (When Math Meets Reality)
In a textbook, the goal is the lowest error possible. In a bank, we must balance that error with four critical real-world constraints:
The Overfitting Trap: Because loan defaults happen far into the future and data can be highly correlated, a model might "memorize" the past rather than "predict" the future. We often use Model Intuition to simplify a model or "dampen" certain weights, even if it means giving up some precision on paper. We would rather have a model that fits the long-term reality better than one that perfectly mimics a specific historical dataset.

Consumer Protection & Fair Lending: Federal law prohibits making credit decisions based on "Protected Classes" (e.g., race, gender, sexual orientation, or age). We must strictly eliminate any variables—or "proxies" for those variables—that are impermissible under US law, regardless of how much "predictive power" they might have.
Explainability (Regulation B): If a bank declines a loan, we are legally required to provide an Adverse Action Notice. This means the model cannot be a "black box." The weights must be clear and explainable so we can tell a customer exactly why they were declined (e.g., "Your credit utilization was too high").
The "Shapley" Solution: How do you explain a neural network where thousands of weights interact? Banks often use Shapley Values (SHAP). This mathematical method "backs into" an explanation by calculating how much each feature contributed to the final score compared to the average applicant. It assigns "credit" (or blame) to individual features—like income or debt—allowing the bank to pinpoint the exact reasons for a denial, even in a complex 3rd Gen model.
Model Governance: Banking law requires rigorous validation to ensure accuracy and stability. If a model is "unstable" (meaning its weights swing wildly with small data changes), it will fail governance. Unstable models create massive regulatory costs, so we prioritize steady, reliable models over complex, temperamental ones.
Phase 3: The FICO® Standard & Human "Backprop"
Before neural networks, there was the FICO Score.
The Tech: It is primarily an "old school" Logistic Regression model.
The Human Element: For 30+ years, human analysts have been "feature engineering"—manually tuning the weights of data from the three bureaus (TransUnion, Equifax, Experian).
Systemic Discrimination: Historically, FICO was criticized for favoring "banked" individuals (traditionally white populations). Today, it uses non-bank data (rent, utilities) to include racially diverse folks and immigrants who were previously invisible to the system.
Phase 4: The Evolution of Agency (Human vs. AI)
As modeling matures, we must decide how much Agency (decision-making power) to delegate to the machine. This is about having "Skin in the Game."
1st Gen: Manual Learning (Human High): The bedrock of banking. Analysts use Logistic Regression or Survival Analysis to define the "map." High human agency ensures high attention to detail and "skin in the game."
2nd Gen: Supervised Learning (Balanced): Uses "Ensemble" methods like XGBoost. The machine finds the path, but the human enforces constraints to ensure conceptual soundness.
3rd Gen: Deep Learning (AI High): Neural Networks identify complex, non-linear patterns in unstructured data—the gold standard for Fraud Detection. Here, the human acts as an Auditor and investigator for false negatives.
The Banker’s Caveat: AI is excellent at predicting based on the recent past, but poor at predicting the long-term future. Over time, prediction quality decays and volatility increases. Because the distant future is fundamentally unknowable (think 2008 or COVID-19), we cannot rely on algorithms alone. In banking, Automation without Intuition is a recipe for systemic risk.
Summary Table for Students
Data Science Term | Banking Analogy |
Weights | The Importance assigned to each piece of customer data (e.g., how much the bank "weights" a late payment). |
Forward Pass | Making the Loan Decision: Multiplying data by weights to predict, "Will they default?" |
Loss Function | The Financial Scorecard: The "Penalty" or dollar-cost of making a wrong guess. |
Backpropagation | The "Blame Game": Working backward to find which weights to adjust to lower future error. |
Explainability | Regulation B: The legal requirement to tell a customer "Why" they were declined. |
Overfitting | Memorizing the Past: When a model mistakes a historical coincidence (like "Tuesdays") for a real trend. |
Agency | "Skin in the Game": The level of delegation and accountability between the Human and the Machine. |
Partial Derivative | Individual Blame: How much a single "dial" (weight) contributed to the bank's financial loss. |
Chain Rule | The Paper Trail: The math used to trace a mistake from the final loss back through multiple departments (layers) to the original error. |
Gradient Descent | Strategic Adjustment: The process of turning all the dials in the direction that most quickly reduces the bank's loss. |
Does This Mean I Need To Be a Data Scientist To Be In Banking?
As we dive into the complexities of neural networks and loss functions, you might be asking yourself: “Do I need to be a PhD-level data scientist just to survive in modern banking?”
The short answer is: Absolutely not.
While having a data science background certainly doesn’t hurt—and is increasingly a "force multiplier" for your career—the banking industry needs far more than just coders and mathematicians. In fact, as AI becomes the standard "engine" of financial services, the industry requires a diverse ecosystem of professionals who can manage, interpret, and govern these engines.
The best way to visualize your place in this world is through the “Trainer, Sustainer, and Explainer” framework, pioneered by Tom Davenport (Babson College) and Jim Wilson (Accenture). This framework identifies three critical "Data Science Lite" or "Data Science Free" roles that are essential to the banking process:
The Trainer: Machines don't inherently understand banking regulations like Fair Lending, HMDA, or the emotional nuances of a customer relationship. Trainers are the subject-matter experts who "teach" the algorithms.
Banking Example: A compliance officer who translates complex legal requirements into the "rules" that a neural network must follow to ensure it doesn't develop illegal biases in credit scoring.
The Sustainer: AI is a high-leverage asset that requires constant "care and feeding." Sustainers monitor the health of the models, ensuring they don't "drift" as the economy changes.
Banking Example: A risk manager who monitors a loan-review robot. If the robot starts struggling to read a new type of income documentation, the Sustainer identifies the failure and routes the exception to a human expert.
The Explainer: Perhaps the most critical role in a regulated industry, Explainers bridge the gap between the "black box" of a neural network and the human stakeholders.
Banking Example: An executive or analyst who can explain to a bank regulator or a frustrated customer exactly why a complex algorithm denied a loan application. They give the machine a "voice" that humans can trust.
In the context of this article, whether you are the one writing the code or the one managing the business unit, you must understand the Money (the business objective), the Math (how the machine "thinks"), and the Mistakes (what happens when the teammate fails).
To see how these roles play out in a real-world scenario, let’s look at how a human and a machine might collaborate on a single credit decision.
As explored in Do I need to be a data scientist in an AI-enabled world? (Hulett, 2026), the banking industry requires a diverse ecosystem of roles that go beyond pure data science.
The "Junior Credit Officer" Thought Experiment

The Scenario: You have just been hired as a Junior Credit Officer. Your boss gives you a pile of 1,000 past loan applications. Some are marked with a Red Stamp (Defaulted) and some with a Green Stamp (Paid Back).
Your job is to create a "Secret Formula" (a Model) to predict future applicants. You have two main pieces of information (Features) for every person:
Credit Utilization: How much of their credit card limit they currently use.
Years at Current Job: How long they’ve been with their employer.
Step 1: The First Guess (Forward Pass)
Without looking at the folders yet, you decide both factors are equally important.
Your Weights: You give a weight of 0.5 to Credit Utilization and 0.5 to Job Stability.
The Prediction: You pick up a folder. The applicant has high credit use but has been at their job for 20 years. Your formula averages these out and predicts: "50% chance of default."
Step 2: The Reality Check (Loss)
You open the folder. It has a Red Stamp. They defaulted.
The Error: Your 50% guess was far away from the reality of 100% default. The bank just lost $10,000. This is your Loss.
Step 3: The Adjustment (Backpropagation)
You look at the next 100 folders. You notice a pattern: People with 20 years on the job are defaulting just as often as people with 1 year on the job, but everyone with high credit utilization is defaulting.
The Logic: You realize your "Job Stability" weight is useless, and your "Credit Utilization" weight is too low.
The Action: You "Backpropagate" this error. You turn the dial down on the Job weight and turn the dial up on the Utilization weight.
The "Class Discussion" Questions
Q1: The Mathematical Nudge If you see that your model is consistently underestimating the risk of default, in which direction does Backpropagation move the weights? Does it make them larger or smaller?
Q2: The "Overfit" Trap Suppose you notice that every person who defaulted also happened to apply for the loan on a Tuesday. Your neural network discovers this and gives "Tuesday" a very high weight.
As a banker, do you keep that weight in your model? Why might this be "accurate" for your 1,000 folders but "wrong" for the future?
Q3: The Ethics Dilemma (Fair Lending) You find a variable that is a 99% perfect predictor of default, but it is a "proxy" for a protected class (like the neighborhood someone lives in).
If you remove this highly accurate variable to comply with the law, what happens to your "Loss" (error) in the short term? Why is this a trade-off the bank is willing to make? How does the current administration (U.S. President, Cabinet Secretaries, and Agency heads) impact Fair Lending?
Q4: The FICO Strategy (Arbitrage) How do banks actually use the FICO score? Do they treat it as the final word, or is it just one tool in the box?
As a banker, do you consider FICO the Yes/No score to make a loan decision or do you consider it a competitive indicator and rely on your internal model to identify where the competition is mispricing?
Summary for the Students
By the end of this exercise, the students should realize that:
Backprop is just the model "learning from its mistakes" by adjusting the importance of variables.
Weights are the knobs and dials that define the bank’s strategy.
Banking Reality means sometimes we turn a dial to "Zero" (like the Tuesday or the Neighborhood example) even if the math says it's predictive, because we value stability and fairness over raw accuracy.
Resources For The Curious
1. Visualizing the Math (The "Backprop" Engine)
If you want to see the Chain Rule in action without getting lost in a textbook, these are the gold standard:
3Blue1Brown – Neural Networks Playlist: Grant Sanderson provides the most intuitive visual explanation of how backpropagation actually "nudges" weights. Watch the video “But what is a neural network?” and its sequels on backprop.
StatQuest with Josh Starmer: For a clear breakdown of Logistic Regression (1st Gen) and XGBoost (2nd Gen), Josh’s "triple-bam" explanations are unbeatable for undergraduates.
2. The Banking Industry, FICO History, and Explainable AI
To understand the "Human Backprop" and the history of credit:
Hulett, J. (2026). Do I need to be a data scientist in an AI-enabled world? The Curiosity Vine. https://www.thecuriosityvine.com/post/do-i-need-to-be-a-data-scientist-in-an-ai-enabled-world
FICO’s Official Blog: Search for their posts on "Explainable AI" (xAI). They discuss exactly how they maintain transparency while trying to incorporate modern machine learning.
"The Information-Based Strategy" (Capital One's Origin): Research the history of Capital One’s founding. They were the first to treat credit cards as a big-data problem rather than just a banking problem, effectively inventing the "Arbitrage" strategy mentioned in Q4.
FinRegLab Research: A 2023 empirical white paper by FinRegLab titled "Machine Learning Explainability & Fairness" evaluated how lenders use SHAP to produce compliant Adverse Action notices. They found that SHAP-based tools are widely used to identify the drivers of a credit decision.
3. Ethics, Bias, and Systemic Risk
Since banking is as much about society as it is about math:
"Weapons of Math Destruction" by Cathy O’Neil: A must-read for any data scientist. She explores how algorithms—especially in lending—can reinforce systemic discrimination if the data scientists aren't careful.
The CFPB (Consumer Financial Protection Bureau): Look up their reports on "Algorithmic Bias." It will show you the real-world regulatory hurdles you will face when your model goes live.
4. Philosophy of Risk & Agency
To understand the "Skin in the Game" concept from Phase 4:
"Skin in the Game" by Nassim Nicholas Taleb: This book explores why the delegation of agency to systems (like AI) without human accountability can lead to "Black Swan" events like the 2008 financial crisis.
"The Signal and the Noise" by Nate Silver: Specifically, the chapter on the 2008 housing bubble, which explains why models based on the "knowable past" failed to account for a changing future.
A Final Note to Students
As you move forward in the Business Analytics program, remember: The model is a tool, not a decision-maker. Your value as a future analyst isn't just in your ability to write the code—it’s in your ability to look at a model’s output and ask: "Is this fair? Is this stable? And do I have the intuition to know when the machine is wrong?"
Answer Key: The "Junior Credit Officer" Thought Experiment
Q1: The Mathematical Nudge
The Answer: Backpropagation moves the weights in the direction that reduces Loss. If the model is underestimating risk, it will increase the weights for features that correlate with default (e.g., Utilization) and decrease them for features that correlate with repayment.
The "So What": This is the "Blame Game" in action. The math is simply a series of nudges to align the "Secret Formula" with the Red and Green stamps in your files.
Q2: The "Overfit" Trap
The Answer: No. You must remove the "Tuesday" weight. While it is mathematically "accurate" for your current 1,000 folders, it is a historical coincidence with no causal link to creditworthiness.
The "So What": This is Overfitting. A model that memorizes the past (Tuesday = Bad) will fail in the future when the pattern inevitably disappears. Bankers prioritize Model Intuition over raw statistical accuracy to ensure the model works in the "real world."
Q3: The Ethics Dilemma (Fair Lending)
The Answer: In the short term, your Loss (error) will increase. By removing a highly predictive variable that happens to be a "proxy" for a protected class, your model becomes less precise at identifying risk.
The "So What": This is the Accuracy vs. Ethics trade-off. Banks accept higher mathematical error to prevent systemic bias and comply with the law.
The Regulatory Context: The U.S. Executive Branch (via the CFPB, HUD, and DOJ) oscillates in how it enforces fair lending.
Strict Enforcement Periods: Regulators emphasize "Disparate Impact," holding banks accountable if a model’s outcome is discriminatory, regardless of intent. During these cycles, oversight on "Digital Redlining" is tight, forcing data scientists to be highly aggressive in removing proxy variables.
Lax Enforcement Periods: Regulators may shift focus to "Disparate Treatment," which requires proof of intentional discrimination. In these cycles, banks may have more leeway to use predictive variables, provided they are not explicitly based on protected classes.
The Bottom Line: Because banking models often stay in production for years, data scientists at sophisticated banks typically build to the strictest historical standard. They know that even if the current administration is lax, the next one may not be—and the "Mistakes" of a biased model can lead to massive fines and reputational damage years down the road.
Q4: The FICO Strategy (Arbitrage)
The Answer: Banks use FICO as a competitive indicator, not the final word. They rely on their internal models to find Arbitrage—identifying "Good" customers that FICO mislabels as "Average."
The "So What": If you only use FICO, you are just like every other bank. If your internal Neural Network says an applicant is a 0 (Safe) but FICO says they are a "High Risk," you can offer them a loan that your competitors won't. This is how sophisticated banks "win" the best customers at the best prices.



Thanks for coming to our class! Thanks for sharing about being a banker data scientist!