
The Replication Crisis in Academia: A Premise Problem, Not a Research Problem
- Jeff Hulett

- Sep 25, 2025
- 20 min read
Updated: May 23

The Crisis Behind the Crisis
The replication crisis exposes a fundamental flaw: researchers treat studies as static, retrospective events rather than dynamic, forward-looking updates to knowledge. Over recent history, this challenge has reshaped academia. A large-scale reproducibility project in psychology attempted to replicate 100 studies; only 36% produced statistically significant results. Medicine faces similar hurdles. In preclinical cancer research, investigators reproduced only 11% of 53 landmark studies. Later efforts in cancer biology revealed that successful replications yielded effect sizes 85% smaller than the original findings.
Stable systems in physics or chemistry ensure consistent replication. In contrast, the social and health sciences struggle because human behavior remains dynamic and context-sensitive. These failures serve as symptoms of a deeper issue within research methodology. This article examines the scope of the crisis and the flaws in frequentist statistical assumptions. It explores how Bayesian inference reframes the challenge and analyzes the distortions within academic and industry incentives. The following sections offer a path forward by applying model validation techniques from the banking sector. We conclude by demonstrating how the Dale and Krueger study on selective colleges provides a premier example of Bayesian inference in action.
About the author: Jeff Hulett leads Personal Finance Reimagined, a decision-making and financial education organization. He teaches personal finance at James Madison University and provides entrepreneurial services. Check out his book -- Making Choices, Making Money: Your Guide to Making Confident Financial Decisions.
Jeff is a career banker, data scientist, behavioral economist, and choice architect. Jeff has held banking and consulting leadership roles at Wells Fargo, Citibank, KPMG, and IBM.
Dimensioning the Crisis: Where Replication Breaks Down
Replication struggles concentrate in disciplines marked by complexity and volatility:
Hardest hit: psychology, behavioral economics, biomedical research.
Stable: physics, chemistry, engineering—fields governed by invariant natural laws.
Vulnerable but underexamined: education, sociology, political science, where replication is rare and methodological rigor inconsistent.
Replication breaks down most where human behavior interacts with changing environments—ironically, the very places where reliable evidence matters most.
Replication failures, then, are not just a breakdown in method. They reveal something deeper: our persistent struggle with the limits of knowledge itself. The replication crisis is ultimately a symptom of the knowledge problem—an inability to capture, measure, and update all the information shaping human behavior.
The Knowledge Problem: Searching Beyond the Streetlamp
The central challenge of human affairs occurs because knowledge suffers from the 4 Nevers:
Never Complete,
Never Static,
Never Centralized, and
Never Invariant.
As Nobel Laureate economist F.A. Hayek reminded us, “The curious task of economics is to demonstrate to men how little they really know about what they imagine they can design.”
The Four Nevers
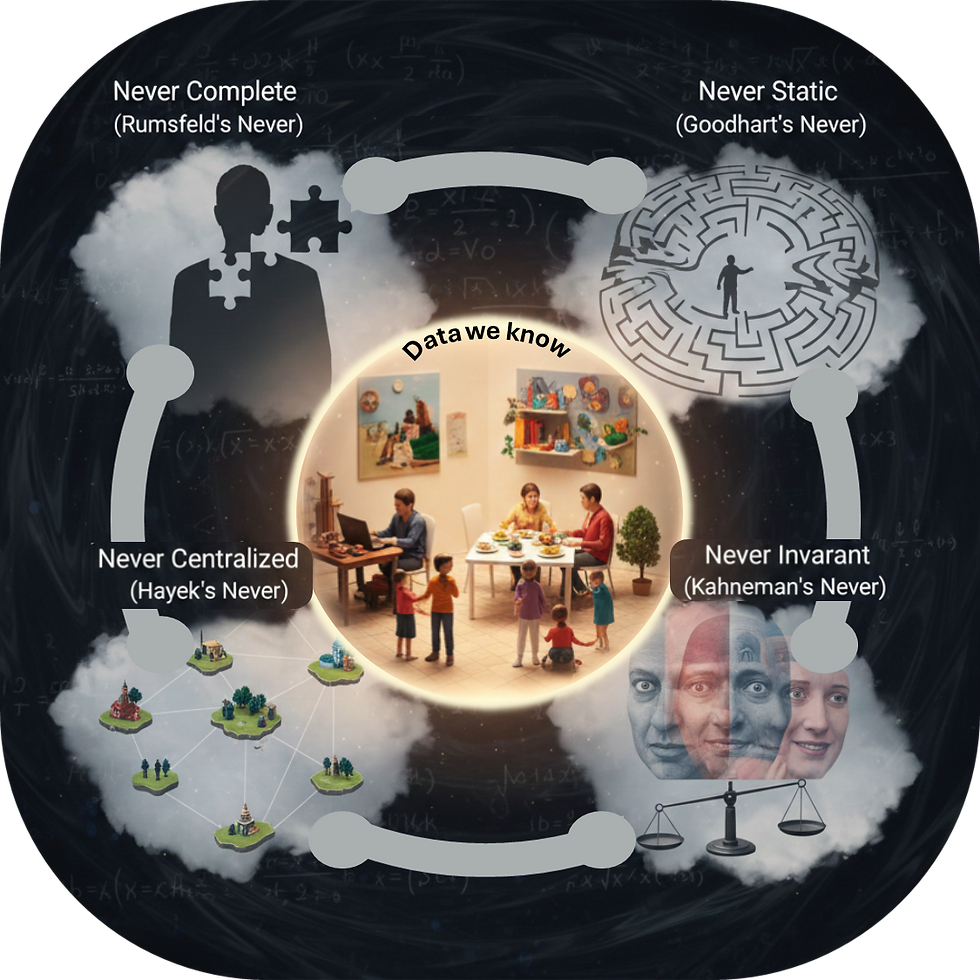
The Four Nevers found in the temporal-based Cone of Uncertainty

We do not know everything we would like to know when making decisions, and the information we lack often matters more than the information we possess. Economists have long recognized this asymmetry, but it applies with even greater force to academics charged with sourcing datasets and conducting statistical analysis. The familiar streetlamp parable captures the dilemma: a man searches for his lost keys only under the light, not because he dropped them there, but because the light is better. So too with research—we often analyze the data we have instead of the data we need for understanding human behavior. In the social world, this challenge is magnified because both the knowns and the unknowns shift continually over time.
As former U.S. Defense Secretary Donald Rumsfeld famously put it, “There are known knowns … there are known unknowns … but there are also unknown unknowns.” It is the last category—the unknown unknowns—looming largest in dynamic, incentive-driven human systems. These shifting gaps in knowledge make prediction fragile and render rigid methods especially vulnerable.
This is why so much of frequentist statistical thinking has been limiting: it tends to focus only on what is visible, like searching for keys under the streetlamp. But knowledge development requires more. Bayesian inference acknowledges our lack of knowledge, incorporates uncertainty, and offers a way to update as new information emerges—transforming research from a fixed snapshot into an ongoing, emergent path of discovery.
The Premise Challenge: Frequentist Fragility
In my career, I spent decades as a deep user of frequentist statistics. My banking teams developed models across the spectrum — from logistic regression to cutting-edge neural networks. These models powered credit risk assessments, credit product demand, fraud detection, and capital allocation decisions affecting billions of dollars. But when you step back from the “how” we built them, the “what” was always the same: using past information, with all its 4 Nevers-based frequentist challenges, to make probabilistic predictions about the future.
This approach worked reasonably well when conditions were stable, such as predicting loan defaults under normal market environments. But when conditions shifted — the 2008 financial crisis comes to mind — the weaknesses of frequentist assumptions became painfully clear. Models trained on past data could not keep pace with new incentives, behaviors, and policy feedback loops. What once appeared to be robust “truth” dissolved into fragility as the ground shifted beneath us. The "Thought Starter from Banking" section later in this article explores how the industry adapted to this reality—developing more dynamic, Bayesian-inspired approaches to model validation and risk management.
How we got here...
Frequentist statistics has long dominated academia. Its roots trace back to the Law of Large Numbers, first formalized by Jacob Bernoulli in Ars Conjectandi (1713). Bernoulli showed under repeated trials, sample averages converge toward a population mean—an insight which became a cornerstone of modern probability and statistics.
This principle worked well for astronomy and physics, where stable natural laws govern outcomes. But it did not stay confined to the natural sciences. In the 19th century, Adolphe Quetelet advanced the idea of “social physics,” applying frequentist methods to human affairs. Quetelet believed human behavior displayed the same statistical regularities as natural systems, producing predictable rates of crime, marriage, or suicide. His legacy was profound: statistics became the language of the social sciences.
Yet this move carried two hidden flaws.
First, human systems are not governed by immutable laws in the same way as planetary motion. They are shaped by priors, incentives, culture, and bias — and, as discussed earlier, they operate within the constraints of the 4 Nevers: knowledge is never complete, never static, never centralized, and never invariant. These realities make human systems adaptive and context-dependent, ensuring models built on the assumption of stability or uniformity will break down. It is a matter of when, not if.
Second, when measurement itself becomes the basis for policy, Goodhart’s Law comes into play. Initially articulated by British economist Charles Goodhart in 1975, the law states: “When a measure becomes a target, it ceases to be a good measure.” The very act of measuring and building policy around a model creates feedback loops. Once a measure becomes a target, people adapt in ways undermining the intended effect. Policy zigs, and those impacted by it zag.
The result is often unintended consequences shifting behavior or markets in directions unanticipated by the original model, leaving the policy response out of sync with reality and, in turn, invalidating the model’s predictions.
Note: Goodhart’s Law functions as an economic application of the Heisenberg Uncertainty Principle. Just as observing a particle alters its position or momentum, the act of measuring a social system fundamentally changes the behavior of the subjects within it. Robert Lucas further formalized this concept through the Lucas Critique, which posits that historical data ceases to provide a reliable basis for policy when the policy itself alters the underlying decision-making rules of the public.
Numerous examples illustrate Goodhart’s Law in action. The Resources section includes a citation highlighting the Civil Rights Act as a prototypical case. By outlawing overt discrimination, the Act turned discrimination into a specific target. Once this measure became the focus, institutions adapted their methods. Discrimination persisted through a transition into subtler institutional forms, such as zoning and land-use regulations. These mechanisms preserve privilege while maintaining formal compliance with the law. The unintended consequence of this shift creates a home affordability crisis. This result burdens vulnerable populations and creates obstacles for the individuals whom the Civil Rights Act originally intended to protect.
When assumption misaligns with reality...
By extending a method suited for stable systems to dynamic ones, social science inherited a structural fragility persisting today.
Frequentist assumptions:
Ceteris paribus: Other factors can be held constant, even though real-world conditions rarely stay fixed.
Stable and generalizable data: Data sets are assumed to be fixed, independent, and identically distributed—ignoring how environments shift and data-generating processes evolve.
Truth through large samples: Larger samples are expected to converge on the “true” result, even if underlying assumptions (independence, identical distribution) are violated.
Validity through significance: Statistical significance (p < 0.05) is treated as the ultimate arbiter of truth, sidelining practical importance or replication.
Model correctness and objectivity: Chosen models are assumed to mirror reality and exclude subjective bias, despite being shaped by human design choices and simplifications.
These assumptions work well in physics. But in the social and health sciences, they struggle:
Human variability: Genetics and epigenetics shape expression, while incentives and constraints in the environment make outcomes inherently dynamic.
Path dependence: Behavior reflects history and trajectory as much as present conditions.
Shifting truth: Findings rest on priors and assumptions rather than a single fixed point.
Constructed data: Data sets are not pure reflections of reality but artifacts of design choices and framing. The "4 Nevers" are the only things we know for sure about any dataset.
Measures as drivers: Once a measure is tied to policy or incentives, people adapt in ways altering outcomes and weakening the link between the measure and its intended purpose.
Under these conditions, significance thresholds are fragile. P-hacking—running analyses until results cross the significance line—is not simply bad behavior. It is the predictable outcome of treating frequentist statistical thresholds as proof rather than as signals.
Even gold-standard tools like Randomized Control Trials (RCTs) face limits. RCTs help identify cause and effect under controlled conditions, but they are vulnerable to the Second Never—knowledge is never static. Once applied in the real world, people adapt, incentives shift, and once-solid results can crumble like foundations turned to sand—an echo of Goodhart’s Law, where measures become targets and human behavior adjusts in ways undermining the original result.
Replication failures expose the limits of the frequentist premise. They remind us “truth” is rarely as stable or singular as statistical frameworks imply.
Relevant to the frequentist challenge, Nobel laureate Daniel Kahneman said it well:
“Invariance is normatively essential, but it is not psychologically realistic. Different descriptions of the same problem evoke different responses, and there is no simple way to make them consistent.”
As a behavioral economist, I consider rationality as user-defined. It emerges from the interaction between our experiences, our genetic wiring, and our present state of mind—each shaping what we perceive as reasonable or true. By its very nature, rationality varies from person to person, just as context and cognition vary across every decision-maker. The idea is a bit unsettling—there is no single “rational” answer. But once we accept rationality as user-defined, the world starts making more sense.
Up to this point, one might be tempted to conclude frequentist statistics are somehow “bad.” This would miss the point. Frequentist methods are valuable tools, but like any tool, their effectiveness depends on context and application. Just as a carpenter (ideally) would not use a screwdriver to hammer in a nail, we should not expect frequentist techniques to perform tasks they were never designed to handle. When applied rigidly to dynamic human systems, they can do damage—contributing to the replication crisis. What is needed is a framework using these tools wisely, while acknowledging uncertainty and incorporating new knowledge.
Bayesian inference offers the path.
A Bayesian Reframing
If frequentist statistics treats research as a backward-looking verdict, Bayesian inference treats it as a forward-looking knowledge journey. The Bayesian framework begins with priors—our current best understanding—then integrates new evidence to update those beliefs. In this way, Bayesianism recognizes knowledge is never fixed, but always conditional and evolving.
Key elements of a Bayesian approach:
Uncertainty retained: Rather than hiding uncertainty behind a binary cutoff like p < 0.05, Bayesian methods acknowledge probability as a spectrum of confidence.
Assumptions made explicit: Priors force researchers to state their starting point openly, bringing hidden biases and framing choices into the light.
Evidence integrated over time: Each study is not a final answer but a step in an unfolding process. Replication failures become expected signals to adjust beliefs rather than discreditations.
Context respected: Because priors can incorporate environmental, cultural, or biological factors, Bayesian inference is more responsive to the path-dependent, dynamic nature of human systems.
This perspective reframes research as an emergent path rather than a point-in-time product. What we understand today should adapt tomorrow, just as human behavior adapts to incentives and environments. Long-term, stable answers are not expected in the social sciences—nor should they be.
Importantly, Bayesian thinking helps dissolve the stigma of replication failure. Instead of treating failed replications as fatal blows, we see them as opportunities for growth, essential corrections for refining models and preventing ossification. Knowledge, then, becomes a living system: continuously updated, sensitive to priors, and resilient in the face of new information.
In this way, Bayesian inference aligns more closely with how human cognition already works. As neurobiology shows, our brains are prediction engines, constantly adjusting to mismatches between expectation and reality. Bayesianism is not just a statistical method—it is a more faithful representation of how belief itself evolves.
As the physicist and Bayesian theorist E.T. Jaynes put it: “The Bayesian view is that probability is an extension of logic. It tells us how to reason when perfect certainty is impossible.”
Frequentist approaches often provide precise local estimates of probability, but these results are typically isolated snapshots—useful in the local time and space—yet fragile over time and across space. By contrast, the Bayesian framework can incorporate frequentist results as inputs while embedding them in a broader updating process. This makes Bayesian inference more resilient, as it adapts to new evidence and changing contexts.
Put simply: frequentist statistics can make us precisely inaccurate—highly confident about the wrong thing—while Bayesian reasoning allows accuracy to emerge across time and space. By continuously updating priors and integrating fresh data, Bayesian methods are better aligned with the dynamic nature of human systems and the pursuit of durable knowledge.
Frequentist statistics vs. Bayesian inference
How frequentist methods are more likely to favor precision, lack accuracy, and lead to a replication failure.

The Incentive Problem
Given the premise is flawed, incentives add fuel to the fire.
In academia, journals traditionally prize novel, statistically significant findings over replications, null results, or incremental refinements—creating a structural bias undermining the long-term reliability of knowledge. Replications, null results, and model updates rarely see publication. Careers depend on publishing “positive” findings, not refining them.
Regarding academic journals, why they behave as they do is very interesting. While outside the scope of this article, suffice it to say journals, like all organizations, are shaped by their incentives and constraints. For a deeper dive, please see the Resources for the Curious section at the end of the article.
In applied fields like medicine, profit incentives reinforce distortion. New drugs can command high reimbursement if trial results suggest efficacy—even when fragile. Industry players push for rapid market entry, crowding out the slower, less profitable work of validation.
The result is a system where initial findings are treated as permanent truths because prestige and profit outweigh long-term credibility.
Toward a Healthier Research Ecosystem
We know information in social systems is incomplete, dynamic, decentralized, and changes for the individual based on time and context. ("The 4 Nevers") Goodhart’s Law and shifting incentives ensure people continually adapt, adding further volatility. By definition, why would we ever expect sciences shaped by humanity to produce static, permanent results? The replication crisis is not an anomaly but a reflection of what we should expect. Bayesian inference, with its capacity to update beliefs in light of new evidence, is a more fitting tool for navigating this dynamism.
Repairing the system requires cultural and structural shifts:
Cultural shift: from “prove it once” to “update continuously.”
Methodological shift: adopt Bayesian frameworks incorporating priors and assumptions.
Institutional shift: reward replication, updating, and transparency.
Educational shift: train students in structured decision-making, integrating tools which reinforce knowledge updating as a habit.
Replication—whether successful or not—should be a core feature of science, expanding the light of the streetlamp so we can search more effectively for our keys, refining, updating, and strengthening knowledge over time.
A Thought Starter from Banking: Models as Living Tools
Banking deserves special mention because it is both a massive user of data and one of the earliest industries to adopt statistical models at scale. Decades before “big data” entered popular vocabulary, banks were applying analytics to guide decisions on credit losses, loan approvals, interest rate risk, fraud detection, and marketing effectiveness. Over time, this approach helped create one of the largest data infrastructures in the world, supported by regulatory regimes demanding model transparency and accountability.
From my data science experience, when models do not validate, it often has little to do with the quality of the math or the mathematician. More often, the issue lies in the assumptions (the priors) and the stability of the data over time. Models frequently fail because they overfit past conditions, making them fragile in new, dynamic environments. I have found less precise models built on more stable data often deliver greater long-term accuracy. Precision and accuracy, therefore, are tradeoffs: precision is easier to measure today, while accuracy requires wisdom and experience because it is revealed only in the unseen future. This distinction matters not just in banking but across disciplines. Academia, too, often rewards precision quantifiable in the short run, while undervaluing the resilience of models able to withstand real-world uncertainty over time.
Because the banking industry runs on probabilistic forecasts grounded in human behavior, banks learned early their models are never perfect—only approximations to be validated, monitored, and adapted as economic environments shift.
Financial institutions today are required to validate predictive models regularly: they must be independently tested, benchmarked, and recalibrated. Importantly, the model validation regime includes strict guidelines for independence—those who validate models must be organizationally and financially separate from those who benefit from the model’s results. This seeks to control the incentive and agency challenge by preventing conflicts of interest. Models are treated as living tools, expected to drift and require updating.
Academic research as a living, dynamic being is no different. Models, like research and analytical approaches, are built on assumptions, priors, and data. Neither should be treated as permanent truth.
The lesson is clear: models are never final; they must be monitored against reality and adapted. If academia adopted this mindset, replication would not be a crisis but a core feature of knowledge.
Banking vs. Academia: How Models Are Treated
Dimension | Banking (Model Risk Management) | Academia (Research Practices Today) | Opportunity for Academia |
Core Assumption | Models are simplifications, prone to drift. | Research findings are often treated as permanent. | Treat studies as living models requiring revision. |
Validation Requirement | Independent model validation mandated (SR 11-7). | Replications rare; null results often unpublished. | Build validation culture into journals and funding. |
Updating Cycle | Continuous monitoring, back-testing, recalibration. | Findings rarely revisited once published. | Institutionalize updating as a norm. |
Governance | Formal oversight by boards, regulators, and auditors. | Minimal, informal, and college-specific oversight beyond peer review. | Create governance structures for long-term validity. |
Incentives | Strong: regulatory penalties for weak validation. | Weak: career incentives favor novelty over ongoing validation. | Reward replications, corrections, and refinements. |
Outcome | Models evolve with shifting environments. | Findings ossify, lose credibility when not replicated. | Knowledge adapts, maintaining trust and relevance. |
Please note: Federal Reserve Letter SR 11-7 provides foundational supervisory guidance on Model Risk Management. It is a good example but also a living document. It is certainly subject to revision, updates, and expansions.
In recent years, many leading journals have begun to respond constructively to the replication crisis. Initiatives such as registered reports, where studies are peer-reviewed before results are known, and data and code sharing mandates are designed to increase transparency and reduce selective reporting. Some journals now publish replication studies and null results, signaling a shift toward valuing validation alongside novelty. Editorial boards have also adopted stricter disclosure standards and encouraged pre-registration of hypotheses, steps mirroring the independence and monitoring practices seen in banking.
While these reforms are still uneven across disciplines, they demonstrate progress toward treating research more like a Bayesian living model—open to validation, recalibration, and updating. In this sense, academia is beginning to align with the mindset long established in banking: models, whether financial or scientific, must be tested against reality, monitored for drift, and updated to maintain credibility.
An Academia Best Practice: Updating Beliefs with Better Evidence
While banking offers a real-world laboratory for testing and refining models, academia provides demonstrations of Bayesian updating in action. One powerful example comes from Stacy Dale and Alan Krueger’s research on the economic value of attending a selective college.
Their studies (2002, 2011) challenged a long-held prior belief: elite colleges cause higher lifetime earnings. By comparing students who were admitted to the same colleges—some who attended, others who chose less selective options—they found the apparent “elite advantage” largely disappeared once student ability and motivation were controlled.
Later, as more data accumulated, their follow-up work refined rather than reversed the insight. The 2002 study results largely validated the conclusion selective colleges had little impact on long-term outcomes. The 2011 study, however, revealed an important nuance: selective colleges deliver meaningful gains primarily for students from disadvantaged backgrounds. Consistent with the “Bayesian” approach illustrated on the right side of the bull’s-eye model presented earlier, D&K’s 2002 study proved accurate but less precise, while the 2011 study increased precision for disadvantaged subpopulations.
This insight has been central to shaping Personal Finance Reimagined’s (PFR) college access strategy—prioritizing first-generation students and communities where college access has long been limited. Applying the same Bayesian logic, PFR directs resources where data indicate the highest marginal impact, helping students make confident, context-aware college choices.
We viewed Dale and Krueger’s findings as evidence resources devoted to less advantaged student populations—time, money, and support—matter more than the selectivity of the college itself. Every institution, selective or not, can improve outcomes by focusing access initiatives on first-generation students and communities historically underserved by higher education.
This is Bayesian updating in its purest form—new evidence adjusting, not overturning, prior belief. The initial model was strong, but subsequent evidence added nuance and precision.
For readers who want to explore how this example maps onto Jeff Hulett’s A/B/C/D Bayesian framework—including a step-by-step GenAI prompt—see the Resources for the Curious section at the end of this article.
Conclusion: The Crisis Is Our Premise, Not Our Proofs
The replication crisis is undeniable. But the deeper failure lies in applying a frequentist premise suited for stable systems to human domains shaped by priors, bias, incentives, and context.
The outcome is predictable: replication rates collapse, short-term incentives reward fragile findings, and public trust erodes.
A Bayesian perspective reframes the issue. Replication failures are not disproofs but signals to update. When combined with validation regimes like those in banking, academia could evolve toward a system where knowledge is alive, adaptive, and credible.
At its core, the replication crisis is a reflection of the knowledge problem—our inability to ever see the full picture, especially in dynamic, incentive-driven social systems. We do not know everything we would like to know, and what we do not know often matters more than what we do. As the streetlamp parable reminds us, it is tempting to search only where the light shines, but true progress requires expanding the circle of illumination.
For social scientists and all who study the human enterprise, this challenge is both bad news and good news. Within the current regime of frequentist-focused journals and rigid research priorities, a failure to replicate appears damaging. But in the larger picture, this is cause for optimism. The dynamism of human systems guarantees research agendas will always be in motion—requiring fine-tuning, updating, and advancing knowledge in step with our ever-changing environment. A failure to replicate is not a death knell but an invitation to grow.
It is both a challenging time and a hopeful time to be a social scientist.
Resources for the Curious
Open Science Collaboration. “Estimating the Reproducibility of Psychological Science.” Science, 349(6251), 2015, aac4716.
Begley, C. Glenn, and Lee M. Ellis. “Raise Standards for Preclinical Cancer Research.” Nature, 483, 2012, 531–533.
Errington, Timothy M., et al. “Reproducibility Project: Cancer Biology.” eLife, 3, 2014, e04333.
Hayek, Friedrich A. The Pretence of Knowledge. Nobel Memorial Lecture, Stockholm, December 11, 1974.
Kaplan, Abraham. The Conduct of Inquiry: Methodology for Behavioral Science. Chandler Publishing, 1964.
Rumsfeld, Donald. Department of Defense News Briefing. February 12, 2002. U.S. Department of Defense Archive.
Bernoulli, Jacob. Ars Conjectandi. Basel: Thurneysen Brothers, 1713.
Quetelet, Adolphe. A Treatise on Man and the Development of His Faculties. Paris: 1835.
Goodhart, Charles. “Problems of Monetary Management: The U.K. Experience.” Papers in Monetary Economics, Reserve Bank of Australia, 1975.
Clayton, Aubrey. Bernoulli’s Fallacy: Statistical Illogic and the Crisis of Modern Science. Columbia University Press, 2021.
Makary, Marty. Blind Spots: When Medicine Gets It Wrong, and What It Means for Our Health. Simon & Schuster, 2024.
Kahneman, Daniel. Thinking, Fast and Slow. Farrar, Straus and Giroux, 2011.
Jaynes, E.T. Probability Theory: The Logic of Science. Edited by G. Larry Bretthorst, Cambridge University Press, 2003.
Board of Governors of the Federal Reserve System & Office of the Comptroller of the Currency. Supervisory Guidance on Model Risk Management (SR 11-7). April 4, 2011.
Frame, W. Scott, et al. “The Technology of Banking: From Information to Knowledge.” Review of Financial Studies, 28(9), 2015, 2561–2597.
Hulett, Jeff. “The Big Shift: How the Civil Rights Act Didn’t End Discrimination, It Just Moved It.” The Curiosity Vine, May 7, 2024. (An example of Goodhart's Law in action)
Hulett, Jeff. Challenging Our Beliefs: Expressing Our Free Will and How to Be Bayesian in Our Day-to-Day Life. The Curiosity Vine, 2025.
Hulett, Jeff. Embrace the Power of Changing Your Mind: Think Like a Bayesian to Make Better Decisions. The Curiosity Vine, 2025.
Hulett, Jeff. From Good to Great: Navigating AI’s Precision While Tackling Hidden Bias. The Curiosity Vine, 2024.
Hulett, Jeff. “Reaching for the Stars: How Personal Finance Programs Can Launch First-Generation College Success.” Personal Finance Reimagined, November 14, 2024.
GenAI-based Deeper Dive Suggestions
For those with an interest in engaging GenAI as a thought partner, next are GenAI prompts engineered to help those who would like to dig deeper and have a little fun with their favorite Generative AI applications.
Academic journal incentives
Regarding the academic journal incentives mentioned in "The Incentive Problem" section, next is a useful GenAI prompt engineered to provide interested readers more context: Step 1: Provide your GenAI the following article:
Trueblood, Jennifer S., David B. Allison, Sarahanne M. Field, Andrei R. Teodorescu, et al. “The Misalignment of Incentives in Academic Publishing and Implications for Journal Reform.” Proceedings of the National Academy of Sciences 122, no. 5 (January 27, 2025): e2401231121. https://doi.org/10.1073/pnas.2401231121 Step 2: Provide the following prompt (copy/paste):
“You are Thomas Sowell, a world-renowned economist, focused on how incentives and constraints impact behavior. You recently read the Trueblood article - The Misalignment of Incentives in Academic Publishing and Implications for Journal Reform. Considering this article and related work, explain why academic journals prioritize novel, statistically significant findings over replications, null results, or incremental refinements. Include the role of incentives, reputation, competition, and structural constraints in shaping editorial decisions. Provide the results in the form of 10 or fewer high-impact dot points. The language should be for explaining to a curious person with a high school education.”
Dive Deeper: Dale & Krueger through a Bayesian Lens
The Dale and Krueger studies offer one of the clearest real-world examples of Bayesian updating in action in an academic setting. Their work on college selectivity shows how strong priors, new evidence, and changing contexts interact to refine our understanding over time. Rather than overturning earlier conclusions, their findings illustrate how knowledge evolves through disciplined belief revision—a process at the heart of decision science and Personal Finance Reimagined. The following resource invites readers to explore this dynamic learning process step by step.
Step 1: Provide your GenAI these sources:
Hulett, Jeff. “Embrace the Power of Changing Your Mind: Think Like a Bayesian to Make Better Decisions, Part 1.” The Curiosity Vine, 2023. Primary guide to the A/B/C/D belief-updating framework (Prior → Likelihood → Baseline → Posterior).
Dale, Stacy, and Alan B. Krueger. “Estimating the Payoff to Attending a More Selective College: An Application of Selection on Observables and Unobservables.” Quarterly Journal of Economics 117 (4), 2002, 1491–1527.
Dale, Stacy, and Alan B. Krueger. “Estimating the Return to College Selectivity over the Career Using Administrative Earnings Data.” NBER Working Paper No. 17159, 2011. (An expanded, out-of-time validation with richer longitudinal data.)
Step 2: Use this prompt (copy/paste):
You are a Bayesian guide. Using Jeff Hulett’s A/B/C/D belief-updating framework (Prior → Likelihood → Baseline → Posterior) and Dale & Krueger (2002; 2011), explain why the selective-college earnings premium is conditional — small on average, larger for some groups — and how new evidence refines, rather than reverses, our understanding over time.
Task: In 10 or fewer crisp dot points, show how this research exemplifies Bayesian inference as a positive, iterative process of learning:
Identify the Prior (A) many people hold (“elite schools always raise earnings”).
Summarize the Likelihood (B) evidence from D&K: admissions/choice data, matched peers, and results showing little average premium once student ability and motivation are controlled.
Spell out the Baseline (C): how common high earnings are among similarly talented applicants regardless of attendance, and how this moderates belief updates.
State the Posterior (D): modest average effect but heterogeneous benefits (e.g., larger gains for disadvantaged, first-gen, or under-represented students).
Explain how new evidence (2011 update) serves as a Bayesian refinement — adjusting magnitude and subgroup differences without overturning the core insight.
Highlight how context and incentives (networks, financial aid, field of study, geography) shift priors and shape likelihoods, showing updating is expected in dynamic environments.
Note how the framework rewards learning over certainty, replacing “brand bias” (“elite = better”) with structured, evidence-based belief revision.
Conclude with a decision takeaway: treat college choice as a living Bayesian process — each new data point is an opportunity to improve clarity, not prove past beliefs wrong.
Output format: 10 or fewer bullet points. Plain language. No jargon. Each bullet should map explicitly to A, B, C, or D, or to a practical inference or decision insight. Language should be appropriate for a curious high school graduate.
Summary
Bayesian thinking views new data as a feature, not a threat. The Dale & Krueger studies show how careful updates refine our understanding: the average payoff from elite colleges is modest, yet meaningful for students whose priors and contexts differ. Evidence evolves, and disciplined updating turns knowledge evolution into wisdom.
Also, one of my other favorite examples of Bayesian inference in academic research is the Levitt and Donohue studies on abortion's impact on crime.
Donohue, John J., and Steven D. Levitt. “The Impact of Legalized Abortion on Crime.” Quarterly Journal of Economics 116, no. 2 (May 2001): 379–420. https://doi.org/10.1162/00335530151144050.
John J. Donohue, Steven D. Levitt, "The Impact of Legalized Abortion on Crime over the Last Two Decades." American Law and Economics Review (2020) https://law.stanford.edu/publications/the-impact-of-legalized-abortion-on-crime-over-the-last-two-decades/



1 Comment